Related Categories
Related Articles
Articles
Künstliche Intelligenz und Bilderkennung
Die Irrtumswahrscheinlichkeit bei der ("automatischen") Bilderkennung sinkt dramatisch in den letzten Jahren (siehe fallende Fehlerkurve -in Prozent- im Chart anbei):
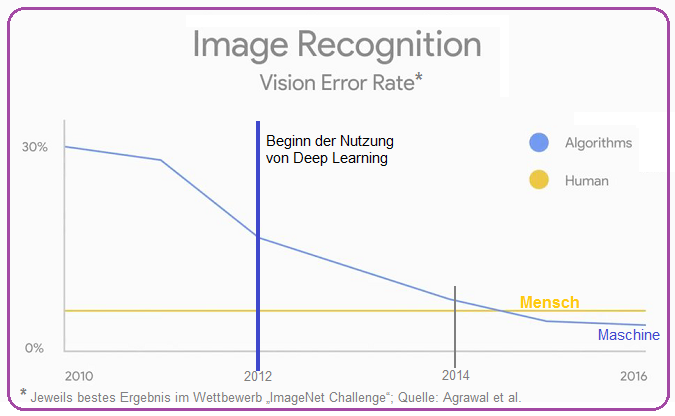
Some words on Machine learning (Figure above; Original text in English)
Machine learning represents a fundamental change from the first wave of computerisation. Historically, most computer programs were created by meticulously codifying human knowledge, mapping inputs to outputs as prescribed by the programmers. In contrast, machine-learning systems use categories of general algorithms (e.g., neural networks) to figure out relevant mappings on their own, typically by being fed very large sample data sets. By using these machine-learning methods that leverage the growth in total data and data processing resources, machines have made impressive gains in perception and cognition, two essential skills for most types of human work. For instance, error rates in labeling the content of photos on ImageNet, a dataset of over 10 million images, have fallen from over 30 percent in 2010 to less than 5 percent in 2016 and most recently as low as 2.2 percent (see Figure above).
Error rates in voice recognition on the Switchboard speech recording corpus, often used to measure progress in speech recognition, have decreased to 5.5 percent from 8.5 percent over the past year (Saon et al., 2017). The 5 percent threshold is important, because that is roughly the performance of humans on each of these tasks on the same test data.
links:
Jahr 2002 (R. Gollner, M. Glaser): www.private-investment.at/app[...]Backpropagation_mglaser_rgol.pdf
https://devblogs.nvidia.com/nvidia-ibm-cloud-support
http://www.nber.org/chapters/c14007.pdf
https://sloanreview.mit.edu/article/unpacking-the-ai-productivity-paradox/



